Decoupling My Commenting System from jQuery
This site utilizes Google Analytics, Google AdSense, as well as participates in affiliate partnerships with various companies including Amazon. Please view the privacy policy for more details.
Ten or so years ago, jQuery (the Javascript framework) was all the rage. Now, removing jQuery is all the rage.
There’s nothing inherently wrong or evil or bad about jQuery. Ten years ago, jQuery could do things that Javascript couldn’t. Well, Javascript could do those things, since jQuery is written in Javascript, then by definition if jQuery can do it, so can Javascript.
But it wasn’t easy in plain old vanilla Javascript. jQuery made it easy.
Now, today, Javascript has evolved. Things that were hard - things that required an entire library - are now easy. So jQuery isn’t as necessary as it used to be.
jQuery is still awesome, but if you don’t need it, it’s bloat on your site. So people have been slowly removing from their sites. Github removed jQuery from their front end back in 2018. I figured, now that it’s 2021, it’s time I start the process.
And I’ll start it with my comment system, since that bit of front-end code exists on every one of my 300+ blog posts.
The Changes
There are three basic changes I need to make:
$('selector')becomes eitherdocument.getElementById('id')ordocument.querySelector('selector')depending on if I’m selecting by ID or not.$('#id').toggle()becomesdocument.getElementById('id').hidden = !document.getElementById('id').hidden.- Change
$.ajaxtofetch.
Changing $.ajax to fetch
Changing the code from the jQuery AJAX call to a vanilla Javascript fetch call was the most challenging part.
I’ll show the changes I ended up making, then I will talk about the problems I encountered along the way.
The $.ajax Call
$.ajax({
type: form.method,
url: form.action,
data: params,
contentType: 'application/x-www-form-urlencoded',
success: function (data) {
document.getElementById('post-new-comment-submitting').hidden = true;
document.getElementById('post-new-comment-thank-you').hidden = false;
},
error: function (err) {
console.log(err);
document.getElementById('post-new-comment-submitting').hidden = true;
document.querySelector('#post-new-comment-error .error-message').textContent = err.message
document.getElementById('post-new-comment-error').hidden = false;
}
});
The fetch Call
fetch(form.action, {
method: form.method,
credentials: 'include',
headers: {
'accept': '*/*',
'accept-language': 'en-US,en;q=0.9',
'content-type': 'application/x-www-form-urlencoded',
},
body: params,
mode: 'cors',
credentials: 'omit'
}).then(response => {
if (!response.ok) {
throw new Error('Network response was not ok:' + response.statusText);
}
document.getElementById('post-new-comment-submitting').hidden = true;
document.getElementById('post-new-comment-thank-you').hidden = false;
}).catch(err => {
console.log(err);
document.getElementById('post-new-comment-submitting').hidden = true;
document.querySelector('#post-new-comment-error .error-message').textContent = err.message
document.getElementById('post-new-comment-error').hidden = false;
});
The Problems Along the Way
And testing in production…
After I made my initial changes, for some reason it stopped working. However, I was (and still am) using the old jQuery code at my Puppy Snuggles site. That call worked.
But using it here, at JoeHx Blog, I was getting a 500 response from the server.
“The server” being a Heroku instance. I could log into my Heroku account and see that it was receiving the call and that it was sending a 500 response. But why?
Maybe I was doing the fetch wrong. For one thing, this is a cross-site call. The Heroku instance is not on the joehxblog.com domain - it’s actually at hendrixjoseph-staticman.herokuapp.com.
During this time, I kept referring to the Using Fetch document on the MDN Web Docs site.
I tried a few things, including sending the payload (the data) as JSON ('content-type': 'application/json') rather than url-encoded ('content-type': 'application/x-www-form-urlencoded'). Oddly, that caused fetch to send two requests rather than one.
This two-request fetch is called preflighting and is a cross-origin security thing. If I only want one request, I had to do a simple request.
My simple request required a couple of things:
- A
POSTrequest. - Content-type to be
application/x-www-form-urlencoded
There goes my JSON request.
It was during this time that I noticed something cool in the Network tab of Chrome DevTools: the ability to copy the fetch call! Simply right-click on a network call, and select the “Copy” submenu of the right-click menu:
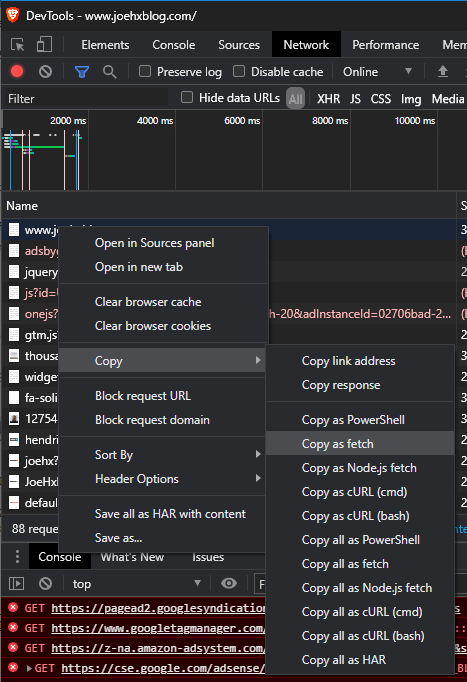
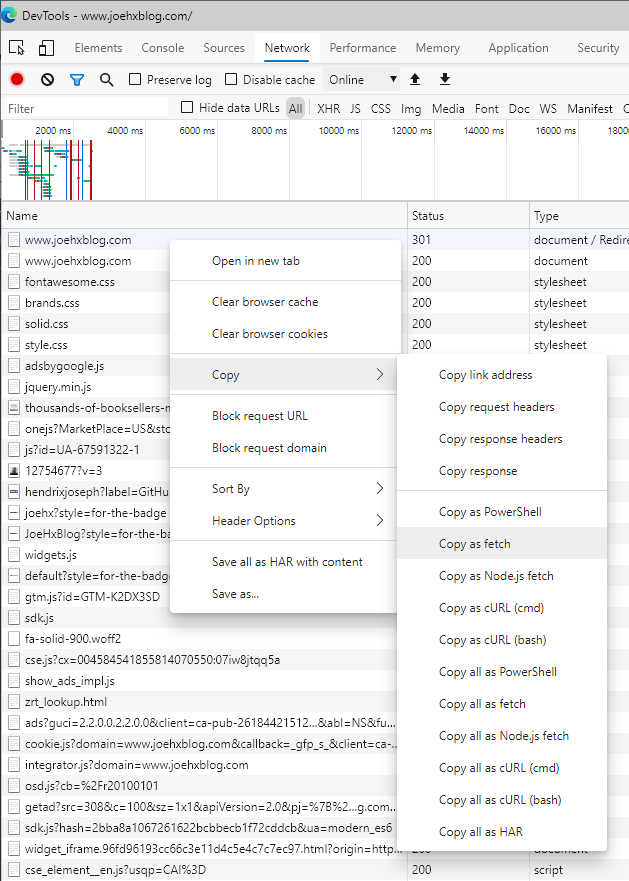
I also checked, and Edge has this as well (unsurprising since Edge is Chrome-based:
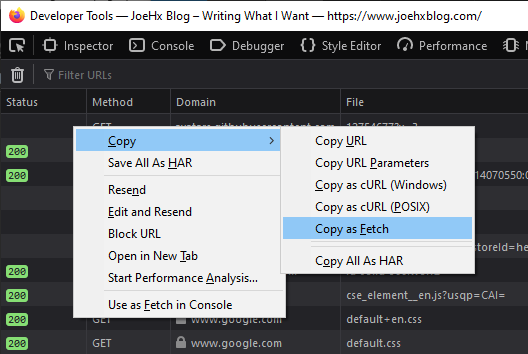
Firefox has it, too:
Not surprisingingly, Internet Explorer does not have this functionality. At least not in the right-click menu.
After I copy the fetch call, remove some superfluous parameters, I’m pretty confident I have my fetch right.
But I’m still getting my 500 server error. It was time to see if the issue was server-side after all.
Let’s Look at the Server
Not-so-fun-fact: Before this adventure, I thought Visual Studio Code was just another advanced text editor, analogous to Notepad++.
What I discovered is that Visual Studio Code can debug Node.js. Notepad++ can’t do that (well, maybe it can).
Previously I’d been (test) running and debugging the back-end code for my commenting system through a combination of Eclipse (via Nodeclipse), Notepad++, and Powershell.
Well, those, and npm and jest.
I couldn’t get Eclipse to debug - that is, allow me to step through and set breakpoints - any Node.js app. With Visual Studio Code, it was easy.
But I couldn’t find any problem locally. The issue was on the server - I needed to step through the code as it ran on the Heroku server.
Can I do it? Yes, I can!
I found a comment on Stackoverflow describing how to connect Visual Studio Code to a Heroku Node.js instance.
How to Connect Visual Studio Code to a Heroku Node.js instance
Note that my start javascript file is called
index.jsand my Heroku app is namedhendrixjoseph-staticman. Yours will most likely be different.
- Edit the Heroku Procfile or the npm package.json such that the node call has the –inspect flag:
Procfile:
web: node --inspect index.jsOr, in my case update the start script in the package.js file:
"start": "node --inspect index.js"
- Run
heroku ps:exec -a hendrixjoseph-staticmanfrom the command line (e.g. Powershell) and then Ctrl-C out of there.- Run
heroku ps:forward 9229 -a hendrixjoseph-staticmanfrom the command line. This will make the app available (for debugging purposes) at localhost, post 9229.- Create a
launch.jsonconfiguration in Visual Studio Code that looks like the following:"configurations": [ { "type": "node", "request": "attach", "name": "Heroku", "address": "localhost", "port": 9229, "protocol": "inspector", "localRoot": "${workspaceFolder}", "remoteRoot": "/app" } ]There now should be a Heroku option in the run configuration drop down in Visual Studio Code.
After stepping through my code server-side, I discovered that the “require english” spam filter I wrote was denying all requests I was making.
So I disabled that filter (I’ve since rewritten and reenabled it), then disabled any tests for that filter, ran my tests, deployed the app, and…
It works!
Leave a Reply